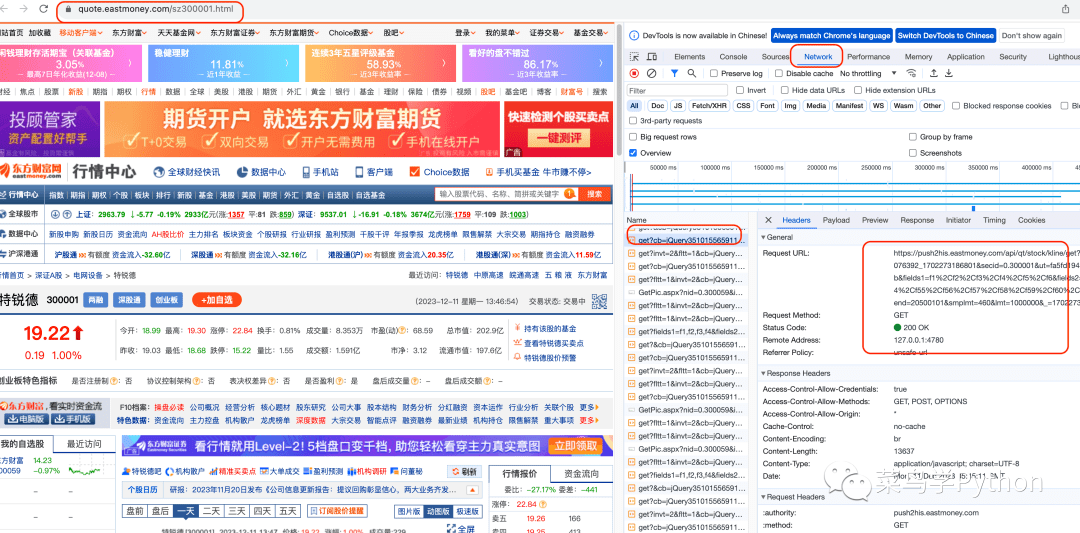
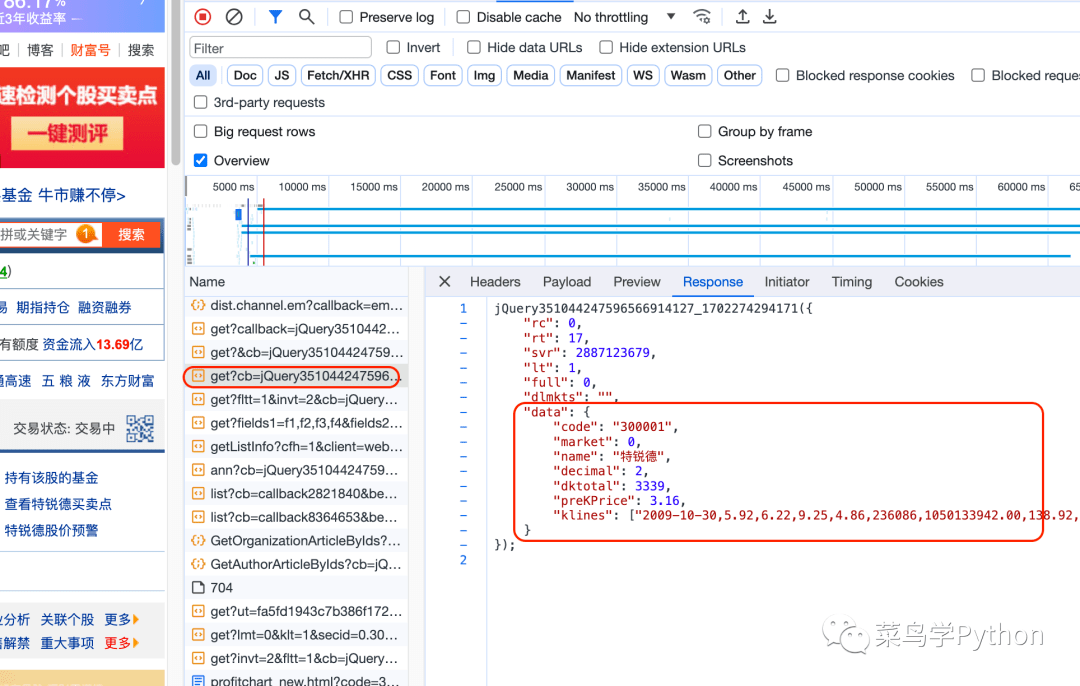
然后检查一下response里面的k线数据,点右边的Response就可以看到具体的data数据信息★。
打开Network 然后刷新网页,找到get★?cb 这样的请求的网页的链接,点开看右边部分★★,有一个Header 看到里面请求的url★★,这个我们要找的链接,把它copy出来。
这么一长串的代码,里面都是复杂的字符★★★,我们看到有一个30001 这个股票代码,其实这个就是我们请求的创业板股票的代码,我们如果要获取多只股票的数据,只要替换这里即可。
假如我们要爬取的股票代码从0-1 ,也就是30,因为创业板默认都是30开头的★★,目前1600多家,我们先爬取一家:返回搜狐★★,查看更多
可以看到很多创业板的股票数据★★,而且是实时的数据★★,我们选一个股票进行分析,比如第一个300001 ★★★,点击打开它的数据。
稍微科普一下啥叫Ajax技术★★★,传统的网页请求是同步的,即用户每次操作(如点击链接★★★、提交表单)时★★★,整个页面都会重新加载或跳转。Ajax 的核心是 Java 的对象,它允许网页在不重新加载整个页面的情况下与服务器交换数据并更新部分网页内容。这意味着可以在网页已经被用户加载之后异步地从服务器请求新的数据或提交数据。
随便找一个空白的地方★★,点击右键,选择检查,进入网页分析页面★★★。可以发现我们不停的刷新页面,网页的内容有变化,但是网页的url完全不变★★★,也就是说该网站采用了Ajax技术★,是动态的从服务器上拉数据的★。
股票的实时数据★★★,历史数据有很多方法可以获取,比如我们可以通过爬虫从东方财富网,新浪财经,或者是券商的qmt软件获取,也可以通过一些专业的第三方的库取获得★★,只是有一些库是需要收费的,最廉价的方式就是通过爬取获得,
上面我们已经找到了最关键的url ,下面就可以开始爬取了,目前东财还是非常友善的★★★,我们不需要伪装headers, 可以直接爬取。